2023情報I 3学期
第6回 授業の振り返りより
質問より
- ワードクラウドのスコア順とは。/ワードクラウドの表示方法として出現頻度順は理解できたが、スコア順とはどのようにして決めたスコアを元にしているのか。/スコアというのはどのように決まっているんですか/ユーザーローカルのテキストマイニングの画面に出てくるスコアが高いというのはどういう意味ですか?
- ユーザーローカルのサイトに説明があります。
- 先生なら何のデータを分析しますか?
- 一番知りたいのは情報のテストと共通テストの得点の相関関係ですね。強い相関がでれば、共通テストへの力を測るテストができているということになりますよね。あ、SSDSEからですか。
- SSDSEは何の略ですか。
- SSDSEは教育用標準データセットのことで、Standardized Statistical Data Set for Educationの略称です。
- 実際のデータ分析プロジェクトで直面した課題や難題、そしてそれに対処する上での経験談を教えていただけますか?
- 教育関係で得られるデータの場合、集団の理解にはつながりますが、個々の分析にはつながらないことが多いんですよね。合否も合計点で決まりますが、足したものは指標であって、能力を正確に測るものではないんですよね。わかっていることとして、タイピングが苦手な人はプログラミングも苦手というということぐらいですかね。
- 情報のページにあるもの以外でおすすめのデータを提供しているサイトはありますか
- オープンデータとしてよく紹介されるのはe-StatやRESASがあります。東京都も東京都オープンデータカタログサイトなどを公開しています。
感想より
- 4人で考えながらこうした方がいいとか意見を出して否定しないブレーンストーミングをもとに話した。自分より発想が豊かな人たちなので自分も納得、安心できるデータ仮説、内容だった。データの相関やもっと違った発想、方法でいい結果をだしたいと思った
- 問題解決の手法が活用されていていいですね。
- なぜか自分の感想で一番出た言葉が「気が付く」に引き続き、「量子化」なのが謎ですね。授業が連続であったからとかなのでしょうか。
- 普段使われない言葉のスコアが高くなる傾向にあります。
- エクセルで文章を選択したいときは1列だけでいいのを初めて知って感動しました
- データを選択することが大切で、それは画面表示とは関係ないんです。Excelのセルには32767文字入りますが、表示は標準で5文字ぐらいですよね。
- 集めたデータを基にしてグラフなどを作り可視化するのが分かりやすそうだなと思った。一つ一つ見ていたら沼にはまってしまうので、そこは効率よくチームメイトと協力しながら進めていきたい。
- データは見始めると「へぇ~」と思うことが多く、驚くほど時間を使ってしまいます。沼にはまらないように、何をどう分析するのか仮説をしっかり立てることが大切です。
- 多少強引かなと思われる話題でも立てようと思えば仮説が立ってしまうことに少し恐ろしさを感じました。こじつけってこういう風にできるのかなとも思いました。
- そうですね。でも相関があっても「疑似相関」だと見抜かれる可能性が高いですよね。
- 自分たちで仮説を立ててグラフにしてみて、失敗したが、とても楽しかった。
- いいトライですね。こういうのを積み重ねてデータを扱う「勘所」をつかめるといいですね。
- SSDSEってOPEC(オペック)みたいな感じで読めるわけでもないアルファベット5文字だと逆にわかりにくいから「教育用標準データセット」のほうがよくねって思った。
- 「SSDSEでPPDAC」ってなんだかすごい授業やっているみたいで、良くないですか?
- データがあればあるほど統計はしやすいというわけではなくて、必要な情報の取捨選択が重要になってくるんだと言うことを実感した。
- データの分析とは、数字をただ眺めるのではなく、複数の違うカテゴリーのデータや同じカテゴリーの違う値を比較し、関係性を探し、なぜそうなのかを思考することだと思った。どのデータ同士が相関関係がありそうかを見極めるのが難しい。
- Excelの膨大なデータを考えなしに見始めてしまうと、何を調べたいのか、どうまとめるのかわからなくなってしまうことが分かった。まず調べるテーマを確定し、そのために必要なデータのみをExcelのデータから得ることが必要だと感じた。今回、日本の海産物の県別消費量に着目して調べたが、海岸沿いだが人口の少ない都道府県より、内陸だが人口の多い都道府県の方が消費が多い傾向があり、一人当たりの消費量を計算しないと求めている結果は出ないかもしれない、と思った。
- データの何が面白いのか全く分かっていなかったが、いじり始めるとデータの相関とか考え始めて、全く進まない。先生の言ってる沼が良くわかりました。
- やりたいテーマは見つかっても、どのように分析するかが難しかった。しかし、同じエクセル内(SSDSEにおける1項目)で比較対象を両方探すと必ず共有する独立変数(所得と死亡について分析するならば(所得関数をf(x)、死亡関数をg(x)とし)どちらも都道府県という項目を共有しているように、同じ独立変数の集合を持っている)を持っているため、実際に分析できるか、またはどの技を駆使するかなどあまり考えなくてもよく、あまり苦労せずテーマを考えることができた。
- データの分析はこれまでは用意された答えが存在するデータで行っていたため簡単だったが、自分でデータを見つけて自分なりに分析をすることは想像以上に難しいなと感じた。
- テキストマイニングのスコア順がどのように決まっているのか気になって調べてみると、一般的な文章ではあまり出てこないが頻出度が高い単語をランキング化したものだった。スコア順はとても画期的なアイデアだと思った。一般的な文章で出てくる単語と判断される単語のリストが見てみたいと思った。
- データを見る前にどのようなことを調べるか考えるのはとても大事だと思った。人口のついてのデータを見ていたらあっという間に時間が溶けてしまった。
- 自分の今までの授業の振り返りをテキストマイニングにして見てみるとどんなことに気をつけて授業を受けていたのかや、どんなことを普段感じているのかが目に見えてとてもわかりやすかった。部活などでも1日1日の練習を残しておいてテキストマイニングにしてみることでもっと技術の向上ができたりするのではないかと思った。
- SSDSEの家計消費のデータを分析しようとしたが、はじめはデータの数字が何を表しているのかすらよく理解できておらず、何をすればいいかわからなくなってしまった。すぐにデータをいじろうとするのではなく、単位や桁などよく見てどんなデータなのか理解することが大事だとわかりました。
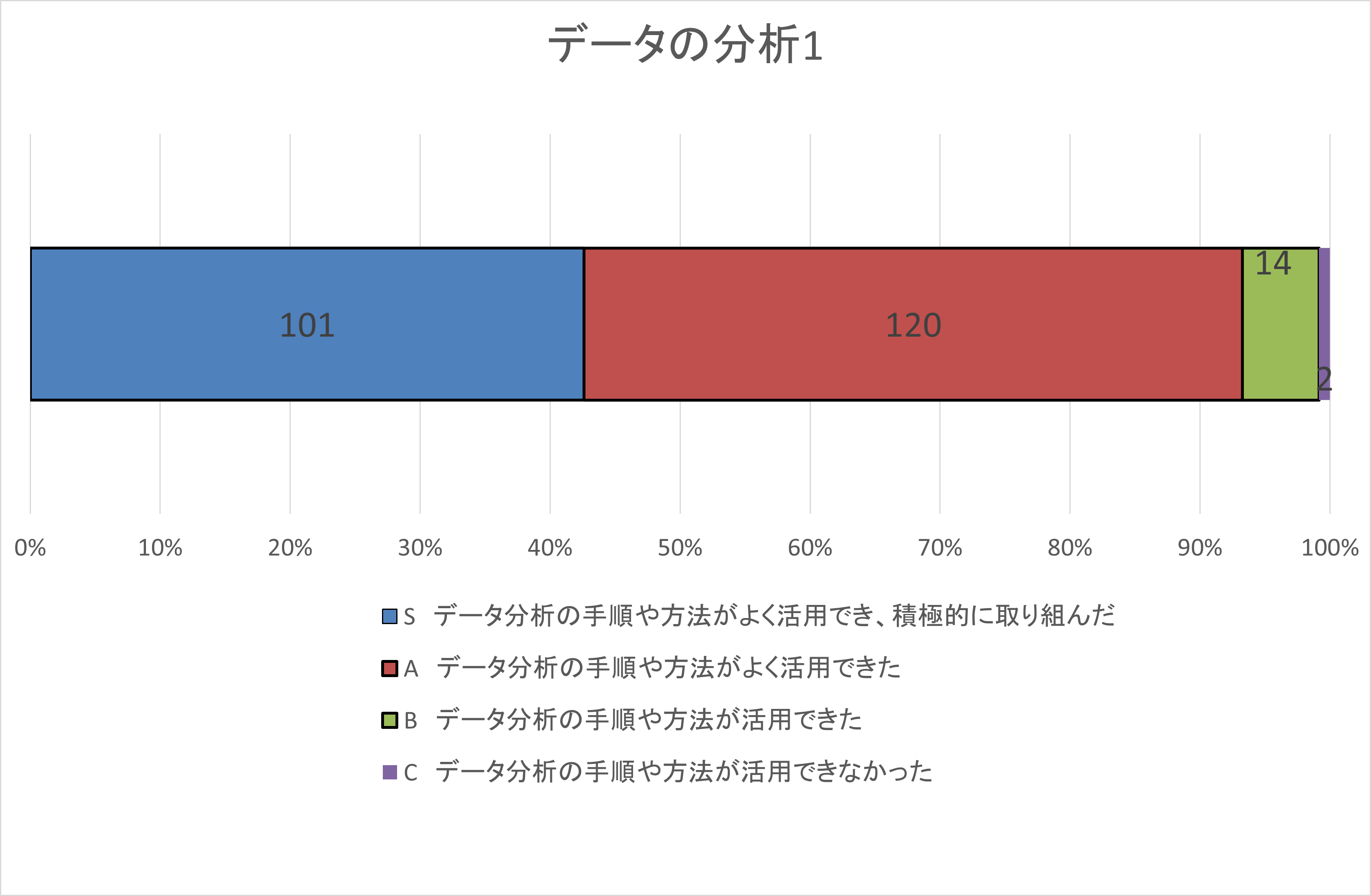
自己評価集計
ワードクラウド
- 3つのキーワード

- 感想や気づき

テキストマイニング 無料ツール by ユーザーローカル
前のページに戻る