2023情報I 3学期
第3回 授業の振り返りより
質問より
- 非構造化データはどのように分析しやすくしているのか。/構造化できない非構造化データはどのように処理しているのですか?
- タグ付けしたり、タイトルをつけるなどして構造化する手法がよく使われますよね。
- DBMSで、共有したデータをシステムが認識できる範囲において限りなく同時に操作が行われた場合はどうなる?/DBMSは同時に行われる変更をどうやって区別して、どうやって順番を決めるのですか。
- 同時は存在しません。ほんの少しであっても、先に処理を開始したものが優先され、他の処理にロックをかける仕組みになっています。
- 非構造化データは、刻一刻と変わっていくデータのことを言うのでしょうか?非構造化データの定義があやふやです。
- 構造化できないデータが非構造化データです。構造化データは簡単に言うとテーブルの形に整理できるデータです。
- 構造化データと非構造化データのところで、有効活用するための技術開発が行われているとありましたが、具体的にどのようなものですか。
- たぶん授業でも話しているはずなんですけど、AIで中身を解析して構造化データを付け加える方法や、構造化しないでデータを格納できるNoSQLなどの新たな仕組みが開発されています。
- DBMSの略ってDMSじゃダメだったの?
- データベースはDBって書くので、Dだけじゃ足りないんですね。
- データベースが故障して誤作動を起こしていてもそれを正常だと信じていた場合、故障に気づけなくなるのではないでしょうか。
- そうですよね。それをチェックするための仕組みもあるはずです。それがないと、イギリスのえん罪事件のようなことが起きますよね。
- Excelで資料を作るときに、F4を使うべき時とつかわなくてもよいときの違いがよくわからないです。
- F4キーのことは忘れて、表を作ってみてください。式をコピーしておかしなことになるときは、どこかでF4キーを押す必要があったと考えればよいのです。
- n次元やm次元の話題が出てきましたが、これらはコンピュータのシステムにどのような影響がありますか。またコンピュータがその知識を取り入れることで、なにか問題があれば教えてほしいです。
- ここでいう次元は空間としての次元とは全く関係なく、座標を表す括弧の中に数をいくつ書くかというものです。次元が高くなれば当然処理速度に時間がかかりますよね。データの持ち方(表現の仕方)も複雑になります。それでもメリットがある場合と、メリットがない場合があります。
- 非構造化は構造化できないのに構造化っぽく表せているのはタグ付けが関連しているといっていましたが詳しく知りたいです
- タグをつけたら構造化データと同じように処理できるという話です。それだけです。
- 非構造化データが、タグやタイトルなどである程度構造化されているデータは半構造化データに当てはまりますか?
- 半構造化データって何ですか?知ってますけど。ここでは構造化データと非構造化データの話をしているので、それ以外のものについては取り上げません。
- 移動平均のところで、第2四半期と第3四半期の平均を取ることや、もう一つ計算をする方が正確なことが、なぜそうなるのか分かりませんでした。
- 第1第2と第3第4の平均をとったら、第2と第3の間の平均値となります。第2第3と第4、翌第1の平均をとったら、第3と第4の間の平均値となります。第2と第3の間、第3と第4の間の平均をとると、第3の値になるという考え方です。
- データモデルならば階層型データモデルだろうがネットワークデータモデルだろうがなんでも2次元の表としてまとめられるのですか。
- 2次元の表にまとめるのは関係データモデルです。それ以外のデータモデルは別のまとめ方をします。これが基本的な考え方です。授業でも説明したとおり、世の中では関係データベースがよく使われているので、階層型データモデルは階層をテーブルで定義することで関係データベースに格納することもあります。
感想より
- データベース管理システムがあるのに、たまに住所などの個人情報などのデータ漏れというニュースがあるのは、管理システムを利用しておらず紙などで管理してるからなのか、不具合が起きることがあるのか気になった。
- データベースはシステムの裏側で動いているので、そこに直接アクセスできません。不具合があっても漏れ出ることもありません。漏洩するのは、中の人がデータベースから取り出したデータを漏洩させてしまう、アクセス権などの設定が不十分で他人のデータも取り出せてしまう、システム自体に侵入されてしまう、などが考えられます。
- やはりExcelなどは基本的な知識がないと何も使えないし、機能を使えないのは勿体無いと思ったためどのように学ぶことができるのかを知りたい。
- 使いながらできることを増やしていくのが一番の近道だと思います。「こんなことできないかな?」と思ったら、ネットで検索すれば出てきます。教則本のようなもので学んでも、使う場面がなければ役に立たないのです。
- 「共有したデータを同時に操作しても矛盾が起こらないよいうにしてくれる」とか、「データとプログラミングを分けて管理し、障害から守る」とか、「不正データの登録、更新を防ぐ」とか、いっちょ前なこと言っちゃってるけれど、要は「窓口を一個しか設けていない」「データベースを動かすプログラミングとデータを管理するところを分けて、ちょくちょくバックアップしてる」「データのチェックを行えるデータを他のところで保管している」だけだし、あれ、あんまり大したことないんじゃないDBMS。と思った。
- それを数万人が利用しても遅漏なく処理できるんです。やっていることはその通りで当たり前のことなんです。
- teamsのエクセルファイルの一つの枠に複数人同時に入力できなかったのは、データベース管理システムが共有したデータを同時操作しても矛盾が起こらないようにしていたからだと分かった。
- 素晴らしい気づきですね。Teams上のExcelってExcelのようで実は裏でデータベースが動いていて、1つ1つのセルを管理しています。矛盾が生じないよう、同時に入力できないよう処理しているんです。よくオンライン上のExcelを偽Excelなんて言っていますが、Excelとしては機能が劣るのですが、システムとしては本物のExcelよりすごいんです。
- エクセルの使い方は理解しているが、算数ができないせいで式が書けなかった。式を立てれるように割り算をがんばりたい。
- 割と単純な式でも「立式」するって難しいみたいですね。特に割合の計算など、算数の部分で苦しむ人も多いみたいです。数学では出てこなくなったかもしれませんが、情報や理科、探究などでも使うので、ちょっと復習した方が良いかもしれません。
- データベースについて学ぶと同時に、エクセルの使い方も復習することができてとてもよかった。移動平均は、変動が大きすぎて折れ線がギザギザしてしまっている場合、変化を見やすくするために役立つものである。中央移動平均や前方移動平均、後方移動平均の3種があって、授業でやったのは前方移動平均かなと思った。
- よく調べてますね。こうやって学びを深めておくと身につきますよね。授業で求めた移動平均は前後の値の平均なので、中央移動平均となります。
- 今回は様々なデータモデルについて学んだが、DBMSがプログラムとデータを分けて管理して、個々で障害を復旧しているといっていたが、そもそもDBMSのプログラムが壊れた場合はどうなるのかなと気になった。
- プログラムが壊れた場合は、予備機のプログラムを使うことになります。壊れる原因としてはネットワーク障害などシステムの部分なので、そちらの障害を復旧してから、プログラムの再起動となります。
- 今日は間違えた範囲を予習していたから、今日の範囲を吸収しにくかった。みんなの質問を聞いて理解できたから、よかった。次回の範囲はもう予習をしているからもう一度見てちゃんと理解したいと思った。
- このところサポートページで次回予告が間に合ってなくて申し訳ないです。予習してわからないことをはっきりさせておくと、頭の中に入りやすいですよね。授業の時間の密度を上げることができて、効率もよくなります。
- DBMSがどのようにして不正データ・アクセスを防いでいるのか気になった。
- 基本的にはアクセス権制御で権利がなければ書き込めないといった処理をしています。それぞれのフィールドには型を定めて、適正なデータ型でないと書き込めないようになっています。
- データとプログラムの分離に際して、データ側が破損する場合はあるのか気になった。
- データが破損することだけは避けなければならないので、同時に2カ所に書き込むなどの処理が行われています。また、処理中の障害に対して、処理が完了しなければ処理前に戻す機能もあります。
- 関係データベースが最も使用されていて、階層型データモデルとネットワーク型データモデルの使い分けは特にないということを知った。
- 階層型データモデル・ネットワーク型データモデルも結局リレーショナル型データモデルで整理できてしまうんです。そのため、リレーショナルデータモデル=データベースのように使われているのです。3種類あるとなると、3種類について学びたくなるのが立高生の特徴ですが、ほとんどがリレーショナル型なので、他はそんなに気にしないで大丈夫なんです。
- システム障害の話で、家でNHKプラスを見てると、突然止まったり戻ったりするので、なかなかプログラムが良くならないんだなと思いました。
- NHKプラスは認証の仕組みで苦労しているみたいですね。よく「ログインできない方へ」って出てますよね。ログインできないとお試し扱いで数分しか再生できないんですよね。
- excelを扱う際にもどのようにデータを整理してまとめるとわかりやすくそのデータの性質が現れるのかということを考えるのがむずかしかった。同じデータであっても季節で比べるのか年度で比べるのかで大きく特徴が変わることが面白かった。しかし、逆に言うと正しい分析を行わないと、データについて誤った理解をしてしまうということでもあるのでどのような分析をするべきなのかを考えてまとめることが重要なことだと思った。
- 折れ線グラフの軸について、テレビで見るグラフの軸が明らかに歪められていたことがあったのを思い出したので、グラフやその軸は自分で作って確かめるのが大切だなと感じる。
- 授業内で、「スタート」を開く→「PC」を開く とやったように、私たちの身の回りは階層型データモデルが多いように感じた。
- 階層型データモデルは、会社内での役職(社長→課長→平社員)のような関係で、ネットワーク型データモデルは、生物界での植物網のような関係なのかなと考えました。
- データベース管理システムの役割の一つの、「共有したデータを同時に操作しても矛盾が生じないようにする。」は、ライブのチケットの先着発売とかで役に立っているのかなと思った。データの重複・不正を防ぐとか、アクセス権とか、大事な役割しかないから、DBMSがなくなってしまったらどうなるんだろうとか考えました。
- データというものは一見同じように見えるものでも、実際に比較してよいものと比較してはいけないものが混じっているので、データを読み取るときは気を付ける必要があると思った。
- データベース管理システムはデータの管理、運用、復旧をになっているから、めちゃくちゃ重要な役割をしているんだなと思ったし、そこが機能しなくなったら、やばいんだろうなと思った。同時に操作しても矛盾が生じないという機能は気にしてなかったけれど、そこがしっかりしていないと銀行の振込のときとか確かにおかしくなるから、順番はしっかりしていないとだめだなと思った。
- 莫大なデータをグラフなどにまとめると、長期的にデータを分析できた。探究でも、短いデータに注目しがちだが、グラフなどにして長期的に分析できるようにしたいと感じた。
- 今の情報社会では膨大なデータを扱うようになり、分別して検索によって取り出せるようにしても、多くのデータがヒットするようになってしまったそのためより細かいデータの分別が必要になったと感じます。(調べてても余計な情報が多くあり本当に欲しいものがなかなか出てこないことも多い)
- 以前の私だったら同じ月だけで比べることしかできなかったように思うが、今回の授業で実際に移動平均、前年同期比、差を出してグラフにしてみることで、思っていたよりもわかりやすくデータを可視化できて驚いた。また、こういった計算を繰り返していけばいろいろな場面で最も適切な方法を選べるようになると思ったので、経験を積み重ねていきたいなと思った。
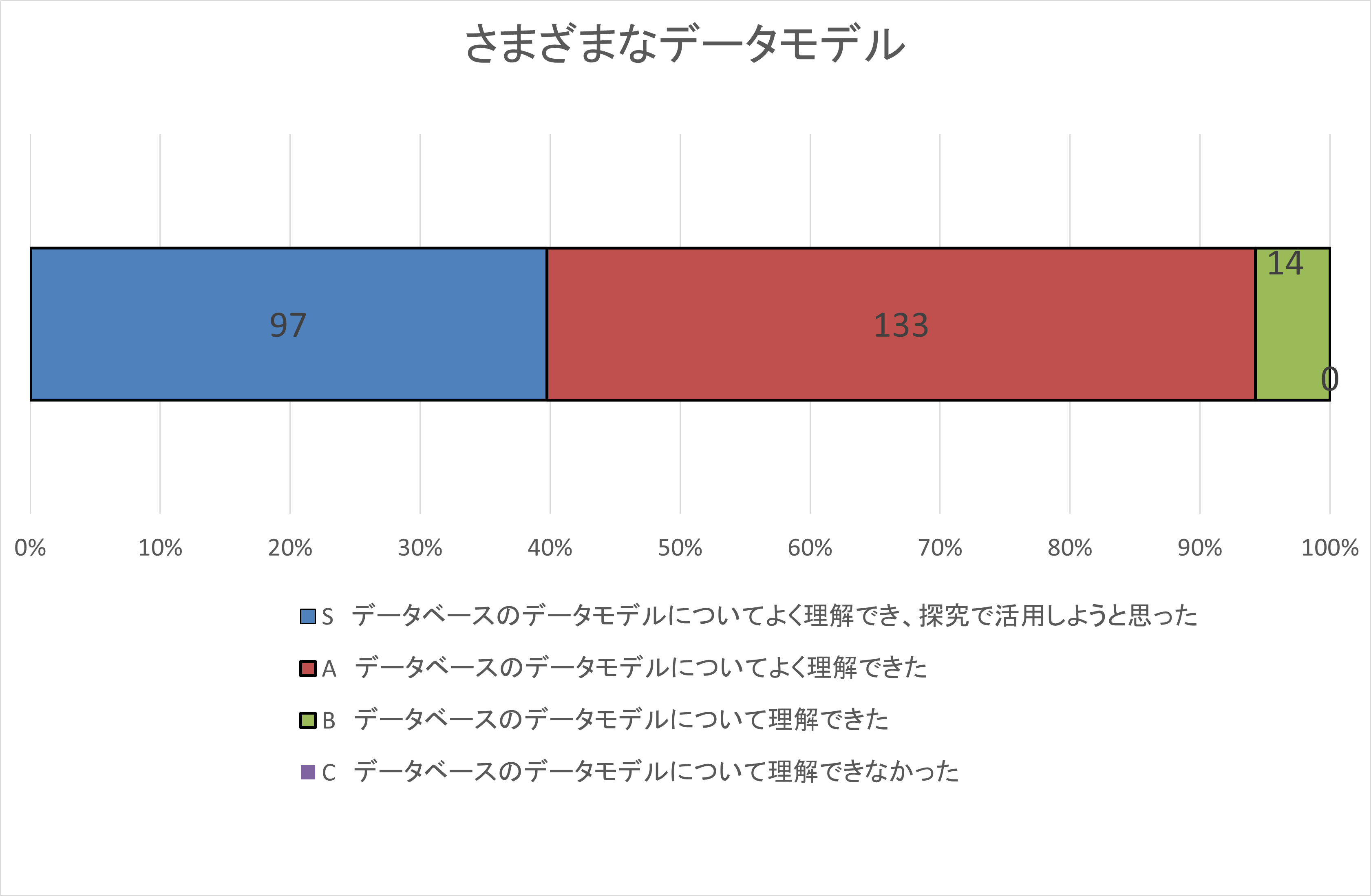
自己評価集計
ワードクラウド
- 3つのキーワード

- 感想や気づき

テキストマイニング 無料ツール by ユーザーローカル
前のページに戻る