2022情報I 3学期
第7回 授業の振り返りより
質問より
無印は皆さんの回答、☆は先生の回答です
- Fは金額に区切りを付けたが他のクラスはどんなことをしたのか
- ☆食べ物と雑貨・甘い食べ物と甘くない食べ物などがありました。同じデータでも視点によって分類が変わり、得られる分析も変わってくるんですよね。
- PPDACの中で最も重視すべきことはどれですか。
- ☆データの分析ですから、A(分析)とC(結論)が大切なのですが、そのためにはD(データ)がきちんと整っていないとダメで、そのためにはP(計画)の時点で適切なデータの集め方が検討できるよう、P(問題)が明確になっていることが必要です。あれ、全部ですね。
- クラス全員で手作業で入力して仕分けたデータはコンピュータではどうやって仕分けるのですか?
- ☆「コンピュータではどう仕分ける」というのはどういうことなんでしょう。コンビニなどで実際の世の中で使われているコンピュータではということでしょうか。コンピュータは仕分けられません。商品を登録するときにきちんと仕分けして人間が入力しているのです。
- チェックデジットの仕組みとは?
- ☆一番右のけたがチェックデジットです。右から1,2,3,・・・と番号を振り、偶数番の数を足して3倍し、チェックデジットを除く奇数番の数を足します。この結果の1の位を10から引いた1の位がチェックデジットです。
- データを分類するシステムってあるのですか?
- ☆ChatGPTに聞いてみました。「はい、データを分類するシステムは存在します。これは、機械学習やデータマイニング技術を使用して、大量のデータを特定のグループに分類することができます。例えば、文書分類、画像分類、音声分類などがあります。これらのシステムは、訓練データを使用して、分類アルゴリズムを学習します。学習が完了すると、新しいデータを入力することができます。これらのシステムは、入力データを正確にグループ分けすることができます。」だそうです。正確に分類してもらうには、正確で大量の訓練データを用意する必要があります。
- バーコードの数字は永久に残るのか疑問に思った。
- 同じバーコードを使いまわすのかという意味の質問ととらえました。市販の異なる商品のバーコードは重複しませんが、同じ商品は同じバーコードだと思います。(バーコードの数字は統一規格で決まっているようです→JANコード) コンビニなどの特別なバーコードは違うかもしれません…
- 外れ値は他の値から大きく外れた値なので、これは欠損値にも当てはまることでもあるため、欠損値は外れ値の一種という認識で合ってますか?
- ☆違います。別のものです。外れ値は値があります。欠損値は値がありません。
- 教科書には二つのバーコードがありますが、なぜ二つ必要なのですか。
- ☆本のバーコードは書籍JANコードといい、上のバーコードがISBNコードといい、本を特定する番号で、下は分類や定価など、販売のためのデータが入っています。
- 今回分析したデータは、家庭で購入したものも含まれているので、他のクラスで挙がっていた「5000円以上の商品は高校生のお小遣いを超えているため、お年玉をつかっているのでは」という分析は無効なのではないだろうか。
- 厳密にいえばそうだが、そういう発想が出た時点ですごいと思う。
- 今日の学習のように、コンピュータは分類分けをすることができないからネット上のグラフなども人間が分類しコンピュータが統計したものなのか疑問に思った。またそれでは人それぞれの個人差があるから正しいデータではないのでは?
- ☆政府統計などは入力者が正確に分類できるよう、条件がしっかり設定してあります。後からみんなでそれぞれ判断して入力するものとは違います。今回の実習で、データの集め方を計画することの重要性が理解できたと思います。
- 授業でやったようなデータの分析は企業などでも同じようにやっているのですか。
- ☆データを属性に分類して分析することはよくおこなわれますが、分類を手分けして手作業で入力するようなことはないと思います。別のデータベースのデータを入手(有料だったりします)して結合するなど、合理的で正確な分析をすると思います。
- 情報Ⅰのページのスライドに11枚目に「因果関係 かき氷の売り上げが増えると熱中症が増える」と書いてあったが、これは因果関係とは言えないのではないか。(どっちも暑い日に増えるから相関が見られるだけで、熱中症の人がかき氷を買うわけでも、かき氷を買う人が熱中症になるわけでもないはず)
- 因果関係と間違えやすい、擬似相関の例として上がっていたのではないか。
☆こういうのは疑似相関です。と説明しましたが。
- 先生が握ているデータにはどのようなものがありますか
- ☆そりゃ、いろいろなデータです。守秘義務があるようなものもあります。
感想より
- 今年度から始まった、都立高校のスピーキングテスト。何らかの理由で受験ができず、スピーキングテストの点数が「欠損値」となってしまった人は当然でてくる。その人のスピーキングテストの点数は、英語の成績が近い(? だったような)5人のスピーキングテストの点数の平均を割り当てることにするとされている。本当の実力をはかることができない点で問題なのだが、欠損値を埋める方法としては間違っていないようにも思える。 とはいえ、課題であることは変わりない・・・
- 欠損値があるとそのままでは処理できないときは、欠損値の補完方法をあらかじめ決めておきます。スピーキングテストの点数についても、そのようにあらかじめ決めたということですよね。欠損が出ないよう皆で努力するのですが、欠損を0にできない場合、このような対応がとられます。
- sAccessを用いることで仕分けしたデータは一瞬で並び替えることができ、便利だった。しかし、商品をジャンル分けするのは、人力で不便に感じた。バーコード番号からある程度の仕分けをできないのか疑問に思った。
- バーコードからメーカーを調べることはできますが、メーカーから商品のジャンルを決めることはできません。例えば無印良品やダイソー、アイリスオーヤマなどは雑貨から家電、食品などを扱っているので、メーカーを分類できても、ジャンルの分類にはならないんです。
- クラスで話し合って進めていく授業はペアにならない人の意見も聞けたり、楽しかったです。バーコードデータは情報の集まりとはいえ、データクレンジングするには手作業で、不思議な気分になりました。(今日の授業でバーコードのはじめが4であれば日本製とおっしゃっていましたが、バーコードのはじめが40~440であればドイツ、45・49が日本、480がフィリピン、489が香港などなど、はじめが4でも日本とは限らないそうです。)
- スイマセン!説明が雑でしたね。「4で始まらない怪しげなものを削除」しました。他の国の商品も許容しているので、日本以外を削除することもできず、結構面倒でした。
- 商品データを分類・分析するときに、商品名→ジャンルごとに分類するのは、人間が手動でやらなければならないため、効率が悪く、時間がかかる。ただ、大事な情報ではあるので、これをAIにやらせればよいが、そんな簡単なことではない。sAccessでは、データをExcelファイルとしてダウンロードできた。なので、バーコードや価格などの数字データを用いて分類する時には、Excel×Pythonで作業を効率化・自動化したらよいと思った。興味が湧いてきたので自分でsAccessを使って色々活用してみたいと思った。
- いいですね。私がデータクレンジングに使ったのもExcelです。sAccessは絞り込んでデータを更新する機能がないので、Excelを使った方が便利です。ExcelのバーコードデータをPythonで検索してスクレイピングして商品名を正しいデータにするといったことができるかもしれません。
- PPDAサイクルについて、Analysis(分析)は誰がやっても同じ結果が出るけど、Conclusion(結論)は人それぞれの視点によって異なるという話がわかりやすかった。
- 今回はクラス単位で問題解決に向けて話し合う場になり、バーコードから国が特定できるという自分の知らない知識だったり、お小遣いの平均から、新しく分けた項目の数値の基準を考えるという普遍性がある分析に使える思いもしなかったアイデアだったり、一人では思いつかないようなことが聞くことができて、大人数で話し合うことで得られる多種多様な知恵の恩恵を改めて感じた。
- 40人で共同作業できるのがすごいと思った。なにを追加して、どう分析するか、今まであまりしたことのない体験だった。けれど協力してうまくやり遂げられたと思う。協力プレーはおもしろいしためになると思う。
- PPDACサイクルを意識して物事を考えるといいことを学んだ。このサイクルは、行動経済学での効果的なナッジを決めるときとの手順と似ていると感じた。つまり、問題を解決するときの根本的な考え方は変わらないのだと感じた。
- PPDACの中でも、問題を自分なりのモノにするCの手順が最も大切だと思った。また、データをうまく活用し分析するために技術と知識が必要だと感じた。
- クラスでデータ整理をするときに国ごとで分けてみるのもやってみたいと思いました。
- クラス全体で分析の内容を考えるときに、クラスメートが言っていた分析の内容はどれも自分の考えにはないものであり、新たな気付きとなった。そのため、他の人の意見を取り入れることで考えたいことに対する視野が広がると感じた。
- ジャンルの境目を判断するのが大変でした。はっきりとした判断基準があればもう少しジャンルを分けるのが楽になるのかなと思いました。データのジャンル分けをAIにやらせるにしても基準は人が決めなくてはいけないのだなと実感しました。
- ただ単にデータを取ったら終了!というわけではなくて、むしろデータを取ってからそれをどのように分析してまとめるかのほうが本題なんだなと感じた。
- データの分析は誰でもできるが、人それぞれ見る観点が違うので同じ結果でも様々な分析結果が出るところが面白いと思った。欠損値や外れ値などの値は確認し取り除く配慮が必要だと思った。欠損値や外れ値を含んでしまうと、バーコードデータのように平均の値が大きくなりすぎたり、逆に小さくなりすぎてしまうと思った。今日の実習で食品、電子機器、その他に分けてそれぞれの平均を分析したが、食品の平均が1000円を超えてしまったので、値段のミスか分類のミスがあったのではないかと考えた。また、バーコードデータの最後の一桁は前の7桁または12桁から計算することができると知って面白いと思った。授業で出てきた国コードについて調べたところ、日本は49と45が使われていることが分かった。国ごとに異なる数字がふられているので、バーコードを見ることで原産国が分かると知ることができた。
- データの分析をするときは、今回の授業のように商品名や価格のデータがあればみんなが買っている商品の価格の傾向を考えることができた。逆にこういう分析がしたいというのがあったら、それに合ったデータを集めることが大切だと思った。情報の授業を通じて、探究するにはデータを集めるところまでを重視しがちだけれど、そこから分析して新たな疑問を発見していくことこそが探究なのだなと思った。
- データの分類を考えるのは難しいし、分類をきめても、人それぞれの主観がはいってしまうので、しっかり分類はできないため集計結果を出してもあまり正確ではないと思った。そのため、分類はなるべく人によって変わらない客観的な基準が必要だと思った。
- データをまとめることが「分析」で人によってデータの捉え方が異なるものが「分析結果」ということがわかり、2つの違いを理解することができた。
- データを収集するときには、データの正確性と回答する手間のバランスをとることが大事だと思った。バーコード情報の提出は「課題だから」と思えばいくらか面倒でも取り組むが、任意のアンケートなどはデータを提供してくれる人が気軽に答えられるくらいにすることも大事だと分かった。探究でClassiを使ったアンケートを使用と考えていたから、このことに気を付けてたくさんのより正確なデータが取れるようにしたいと思う。
- データを追加することで、新たな価値を見出すことができるのだと感心しました。今回の授業では商品のカテゴリーで分類し、みんなは冬休みに食品を買う傾向にあることがわかり、面白かったです。
- データを分類するときにバーコード番号をどうにかすることしか頭になかったから、隣の人や発言で「確かにこういう考え方があるのか」と気づいて自分の考えが固まっていて視野が狭いことを知って、話し合うことやグループワークって大切なんだと気づいた。
- みんなで協力するのが少し大変だったけれど、仕切ってくれる子が最後まで指示を出してくれたり、質問に答えてくれたのでとてもありがたかった。膨大な量のデータもみんなで手分けしてやればある程度は分析できるのだなと思った。
- みんなで話し合って項目を決めるのが楽しかった。今わかる情報を分類し新たな視点を見つけるのは、簡単に見えて、やってみるとなかなか思いつかないものだった。クラスの子が言っていた、価格帯で分けて、高校生のお財布事情を探るという視点がとても面白かった。さらに、高校生の平均額で区切るというアイデアが、新たな視点を見出すものでよかった。私も色々考えてみたい。
- 何を分析するかを絞り込み、分担することで、効率的にデータの分析ができることと、きちんとしたデータの重要性に気づけてよかった。
- 項目を後から追加するのは、労力も時間もかかるし、人によって判断が分かれる基準で分類されることもあるので、可能な限り避けるべきことなのだなと感じた。
- 今回の実習を通して、バーコード番号や商品の分類の仕方はたくさんあるはずなのに、いざ考えてみると、情報量の多さからどこに着目すればよいのか分からず、分析までに手間取ってしまいPPDACのうちPPの難しさを実感した。グループで作業を進めるときにおいて、やるべきことが共有されて、各々が把握していれば分担ができるので作業効率は大きく上がるけれど、共有がうまくいかず各々の認識が違っていたりひとりでも欠けていたりすると、混乱したり無駄な手間をかけることになってしまうことを今回深く感じた。また、そもそも目的と作業の仕方が決まらないと全体が止まってしまいその分作業時間が削られてしまうので、反対されてもいいから積極的に自分の意見を出すことと、人任せにしないで常に考えながら作業員の一人として参加することが大切だと思った。改めて考えてみると、四十人ちかい生徒が一斉に作業をしても問題なくページが更新され動作しているデータベースが、いかに大量のデータを保持できるのかが分かった。情報分析するデータは同じでもPPの段階で目的や着目する点が違うと結果は全く違うものになるので、PPの大切さも分かった。グラフだけをみて比例関係にある二つの事象を因果関係にあると判断するのではなく、疑似相関がないかを仮設検定などを使って試すことが、これから先様々な資料やデータを見て、判断していく上で必要なことだということが分かった。そして、それを逆手にとって疑似相関を使って自分の考えを通し、人々を騙すような人はネット上にたくさんいるので、情報や統計学を学んで、おかしいところはないか、因果関係は本当にあるのかなど、分析結果の背景まで考えられる力をつけることが大切なのだと分かった。
- 今回の授業でデータ分析の手法を理解できた。しかし、結果的に回収できたデータは食品の値段の平均が1000円以上であり、明らかにおかしくざっと見たところiPhone13を食品としてしまっているなどのミスが見つかった。データの分析をする際のミスは、結果に致命的な影響を与えてしまうのだと分かった。
- 今日、生徒が買った食品の平均の値段を求めたけど、比較対象がないと大きいか小さいかわかんないから、何かと比べる必要があると、授業が終わって気づいた
- 最後の分析中にデータの入力で全角文字を使っているのが少し見つかったが、すぐに特定して書き直すことができて良かった。定期的な分析も必要だと実感した。
- 授業の中心に立って進行するのは楽しかったが責任を少し感じてみんなに頼ったところがあった。けれどそのやり方は授業を進行していくなら正しいやり方だったのかなと思った。データを分類していく段階で、質問が来るたびに調味料は分けた方がいいかなとか、薬も体内に入れるものだなとか新しい分類の視点がわかり、学びは他人より深まったように感じた。
- 授業時間が45分しかないから仕方ないのだが、時間が迫っていてめちゃくちゃ焦りながら行うデータ分析は疲れるだけで正直あまり楽しくなかった。今回は「データ分析のときはこういう視点が大切」というのを知る授業だったので話は別だが、データを入力する場合はミスも増えるし、傾向などを見出すときも理由がだいぶ雑になったので、探究のときにデータは確保したからあとはのんびり…なんてやって最後にズタボロにならないように気をつけたい。
- 情報の授業でここまで生徒主体な進行が初めてだったから凄い楽しかったし、意欲的に取り組めた。他のクラスの方針をしれたらもっと良かった。
- 食べ物の約半数が甘いものだったことを考えると、やはり高校生の支出にはお菓子が多いのかなと思った。商品名の書き方の指定をすると、項目が追加しやすいかなと思った。回答者にたくさんの項目を入力させればいいんじゃないかと思ったが、入力ミスを考えると、データ収集そのものが難しいと感じた
- 数学で、コンピュータにやらせればよいような分析の計算方法などを学ぶのは、分析という作業じたいは誰が行っても同じ値が算出できるが、そこにどんな因果関係を見出すかは個人の視点によって異なり、自らデータをどう活用するかを理解しておく必要があるからだと分かった。
- 探究活動ではアンケートをとって分析する作業が今のところ私は必須なので、情報で学んだデータの分析方法は活用したいと思った。その時はまず分析に適するデータにするところから始めなければいけないのだということにも気がついた。データの集め方や分類の仕方もよく考えて探究に活用しようと思った。
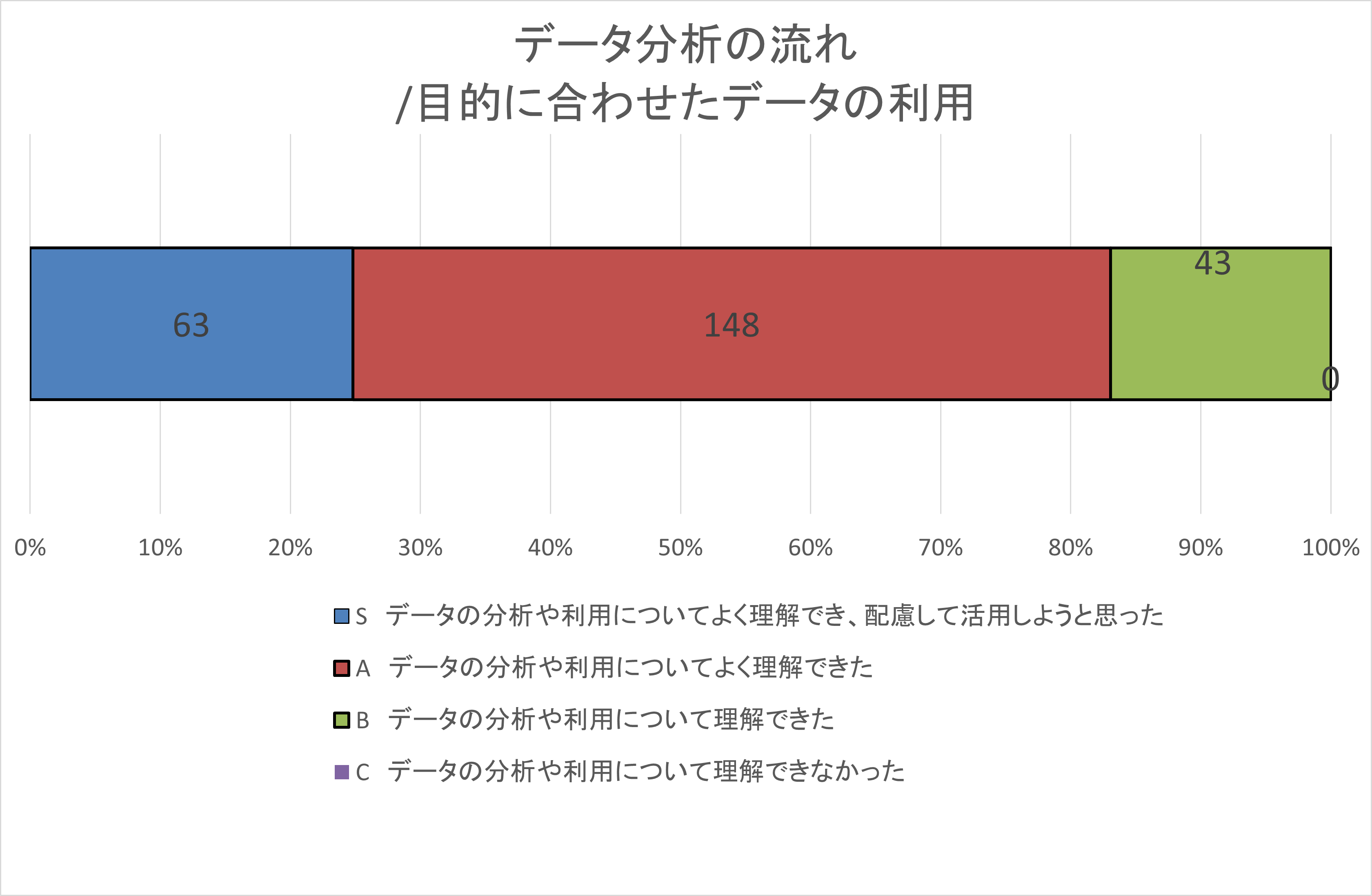
自己評価集計
ワードクラウド
- 3つのキーワード

- 感想や気づき

テキストマイニング 無料ツール by ユーザーローカル
前のページに戻る