2022情報I 3学期
第6回 授業の振り返りより
質問より
無印は皆さんの回答、☆は先生の回答です
- コイントスの乱数を使ったプログラムについて、授業で仰ってたより良いプログラムとはどのようなものですか
- ☆コインを30枚投げた時の表の数を数えるには、numpyを使って以下のようにするそうです。新たな概念が必要になるので、ちょっと授業では説明できません。
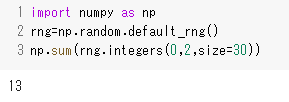
説明はこちらの動画を見てください。
- DBMSのデータとプログラムを分けて管理するということがよくわからなかった。
- ☆電話帳のアプリもデータベースの一種です。アプリによってはデータをプログラムの中で保持しているものもあります。DBMSはプログラムとデータを明示的にわけて保存することで、プログラムに障害があっても、データを安全に取り出せる仕組みになっています。
- なぜ基準となる値が基本は5%だという暗黙の了解になっているのか
- 基本となる値が5%であるということが暗黙の了解になっているのはやはり、教科書での基本となる値が5%とされているからではないかと思います。しかし、5%に合理的な意味はないそうです。
- Twitterの検索で、タグをつけないで検索してもツイートが出てくるのは、ツイートに書かれている単語でタグ付けのようなことをしているということですか。
- ☆当然、単語で検索していると思います。特にタグ付けはしていないと思います。
- 円グラフのはい、いいえは比較ではないんですか。
- 例えば「はいの人がいいえの人の1.5倍いる」という情報がそのデータに含まれているとして、棒グラフならそれが目で見てわかりやすいが、円グラフだと分かりにくい。(=比較に向かない)
☆他の項目と比較することがない、3つ以内の分類のものであれば円グラフも有効であると、授業で説明しました。はい、いいえは同じ項目についての違う回答です。他の質問事項の「はい・いいえ」と比較するのであれば、円グラフは適切ではありません。
- 片側検定と両側検定がよく分からなかった。 /片側検定と両側検定の違いがよく分かりません。疑問を立てたら、なんであってもその疑問が予想ではないのですか。 /仮説検定で、両側をやったほうがいい(主張をする上で)場合はどんなときですか。 /片側と両側の話がよくわかりません。両側とはヒストグラムの両側ということなのでしょうか。
- 片側検定とは2つの選択肢がある中でどちらか一方の結果を調べること。両側検定とは選択肢がどちらであるかは問わず、極端な結果になるのかを調べること。
☆詳しくは数学Bで学んでください。「多いかな」は予測で多い方に偏っているか見るので片側検定です。「違うかな」は予測ではなく多い方だけでなく、少ない方にも偏っていないか見る必要があるので、両側検定です。
- 今回の授業の内容と少し離れてしまうが、スライドに、情報のページにリンクがある (ローカル版)、 js-starで検索(Web版)、と書いてあった。ローカル版とweb版は何が違うのか。
- ☆気づきましたか。消し忘れです。以前からjs-Starを使っているのですが、回線の問題で動作が不安定になることがあり、同じ仕組みをPC室サーバに入れた「ローカル版」を用意していた事がありました。現在は問題なく使えるので、web版だけになっています。
- 関係データモデルはどのようにして、各データを繋げているのか。
- ☆いい質問です。関係データモデルには[リレーションシップ]というものが存在します。販売データと商品データにはどちらにも[商品コード]があります。これを元に2つのテーブルを結びつけます。
- 数学+情報がここまで親密に関わっているのは他にありますか。
- コンピュータって高速2進法計算機ですから、基本的には数学が関係してきます。一番影響があるのは、立式する力だと思います。コンピュータでシミュレーションするには、事象を式で表す必要があります。式で表せれば、強力な計算力でシミュレーションすることができますよね。
- PPDACではなくて、PPDCAではないのですか。
- 分析したことに対する考察、つまり、結論であるから。
☆分析せずに結論が出てしまうのは「結論ありき」の不適切な研究手法ですよね。
- 本当に、新薬の開発や広告の効果を予測するために、実際の社会で仮説検定は使われているのですか。
- ☆「本当に」って人を嘘つきのように言わないでくださいね。本当です。
- 仮説検定が具体的に活用されている職業などが知りたいと思った。
- 統計的な分析は製造・販売会社などで必要だと思います。調べてみたところアクチュアリー(保険数理士)などがあるようです。
☆データを必要とするさまざまなところで使われています。本当は全員について調べたいけど、全員について調べられないときに仮説検定の考え方が使われています。考えてみて下さい。たくさんありますよね。例えば薬の開発・視聴率調査・選挙速報・世論調査・広告の効果測定・研究成果の検証などです。
- 郵便番号も「県→地域→何丁目」と表され、ネット上でも管理されているので階層型データモデルと言えますか?
- 言えると思います。
- 数値化できない情報はどのようにして処理すればいいのか?
- ☆数値化でなくて構造化ということですよね。タグ付けして構造化したり、有用なデータであるならAIで分析したりして傾向を見たりするようです。
- サポートページには、関係データベースは関係モデルによるデータベースだと書いてあるが、この関係モデルとは何ですか。
- ☆教科書にもスライドにも説明がありますが、データベースにはデータモデルというデータを整理する形式があります。関係モデルはデータモデルの一つで、データの集まりをテーブルという表で表し整理するものです。
感想より
- どのくらいの規模になったらサーバーが複数必要になるのか気になった。また、順序性がしっかりしていなければDBMSとして成立しないと聞いて、そのシステムがDBMSとして認められるかどうかというのは何かの機関が判定しているのかなと不思議に思った。そして、写真のタグ付けなど構造化は人間による判断でしか正しくならないと聞いて、コンピューターだからと言って何でもできる訳ではないということを改めて感じた。今まで数学の仮説検定ではなんとなく5%を基準にしていたけれど今日の話で場合によって基準を変えることが重要だということが分かった。
- 規模とシステムの関係は、求める性能によっても違うので、業者さんでなければ分かりません。DBMSは必要な性能を持っていなければDBMSとして成立しないので、メーカーが必要な機能が満たされるよう開発し性能を保証します。性能が低ければ使われないだけです。
- 数学Ⅰの内容がデータの分析関連で違った教科でも扱われることは、数学がまるでできない自分にとっては相当きついことだと感じた。
- まるでできないままにしてはいけない、ということですね。
- 情報において、よく階層構造という言葉を聞くので、階層構造がよく使われているのには何か理由があるのかなと思った。
- プロトコル・データモデル・セキュリティポリシーで「階層構造」が出てきましたが、共通した理由はないです。この3つ、絵に描くと同じ階層構造なのにまったく違う絵が描けます。
- 今までアンケートは、人数だけで判断するものだと思っていた。しかし例えばAとBどちらが優れているかというアンケートをとったとき「どちらを選んだ人が多いのか」という結果は得られるけれど「どちらが優れているか」という結果は仮説検定をしてみないと得られないのだとわかった。これから自分が探究でアンケートをする際は仮説検定を行い正しくデータを分析したいと思った。
- そうです。そこの違いが大きいんです。
- 膨大なデータを処理するのは便利だなと思った。しかしその分それ相応のコンピュータが必要なので家庭などでは無理だなと思った。だから学校が毎年駿台や河合塾などの予備校に共通テストの点数や偏差値などの情報を渡して全国何位とかそういうデータをもらっているのかなと思った。
- 全国何位のデータは、全国のデータを持っていないと分かりませんよね。数万人のデータ処理の問題もありますが、よその学校のデータはもらってこれないので、予備校等で集約してデータ提供を受けるのです。
- 数学の計算が分からず全くついていけなかったので、もう一度復習し直さないとならないなと思った。また情報と数学が相互に関わり合っており、数学の意味が分からない公式は社会ではこんなことに活用できるのだな、と知ることができ、興味深かった。
- 数学が苦手な大人は、「数学なんか世の中に出たら使わない」と言ったりしますが、それは数学が使われていることを知らないだけで、世の中至る所に数学は活用されているんです。例えば、3DCGのキャラクターがグリグリ回るのは、三角関数のおかげなんです。
- 中学の保健体育の授業で体力向上について「PDCAサイクル」という言葉を習ったが、統計的探求プロセスのPPDACはそれぞれのアルファベットの意味が異なっていた。また、PPDACは探求活動においてデータがとても重要な要素だということを示しているなと感じた。実際のSSH個人探求で自分は3番目のD,データ収集の段階にいるから、これからはそのデータから特徴や傾向を把握して結論を導き出せるようにPPDACサイクルの順序を頭に入れて探求活動を行いたい。
- 情報でもPDCAサイクルやりましたよ。立高PRプロジェクトはプレゼンやって相互評価して、改善してWebページを作るものでした。Plan(計画)、Do(実行)、Check(評価)、Action(改善)、P、D、Cまでやっているんです。ここでPDCAサイクルって言うんだよって説明しておけばよかったですね。
- 最初の説明や途中のシュミレーションで思ったが情報という教科はただ単にプログラミングといった技術だけでなく他の教科の内容(数学や思考?)というもの混じってるから少し情報についての印象を変えた方がいいなと思った
- 情報って総合力が必要だったりしますよね。数学も国語も英語も必要ですね。
- 仮説検定はもはや数学でやるよりも情報で扱うべきだと思いました。かなりのデータ量があったとしてもコンピュータで計算し、そこから得られたデータを考えることができるためCPUの計算速度は素晴らしいと思いました。間違っても4桁クラスのデータを人間が扱うと間違えるかパンクすると思います。
- 仮説検定を情報だけでやるのは嫌です(笑)。計算や理論は数学で学び、得られた値の活用を情報でやる、今のような分け方が正しいと思います。値が得られても、それが何を意味するかがわからなければ役に立ちません。
- 数学よりも緩く考えて、数値をあくまで材料として扱う考え方が、情報の特徴なのかなと思った。
- 面白い見方ですね。確かにそういう一面もありますね。
- あまり情報や仮説検定と関係がないかもしれないないが、時々PDACサイクルという言葉を耳にしてきたが、今日授業で扱ったのPPDACサイクルだったことがかなり心に残った。本だったり、講演会では問題を解決するためにはPDACサイクルを使いましょう、PDACサイクルとはこうこうこうで…(必ずしもPDACサイクルという言葉ではなかった)みたいな感じで使われていたが、PPDACサイクルではいきなり問題を解決しようとせずにまず問題がどのようなものであるか、仮説検定で扱えるかをきちんと設定しているのが非常に優れていると感じた。様々な場面で活用できると感じた。
- PDCAサイクルですね。Plan(計画)、Do(実行)、Check(評価)、Action(改善)の略です。立高PRプロジェクトはPDCAサイクルになっていたんですよ。
- 最近ではチャットGPTが話題になっていたりする。これは、だんだんとAIによって非構造型データが構造化する技術が発展してきていることを示すのだと思った。
- chatGPT、なかなか優秀ですよ。ただ、回答が正しいか保証がないんですよね。また、それこそチャットで文字のやりとりだけなので、非構造化データの分析には使えませんね。
- こんなに簡単にプログラムで確率を求められるのであれば数学Ⅰで何をやらされたのか、また何のためにめんどくさい計算を解かなければならなかったのか。むなしくなった。/コンピュータだと簡単に計算できるのにわざわざ数学で計算する自分がアホらしく思えた。
- 何か大きな勘違いをしているようですね。数値を求めることが目的でなく、その数値の持つ意味を考えることが必要とされています。数値の求め方を知らなければ、その数値の持つ意味は分かりません。数学で計算して、計算の仕組みを学んだからこそ、その数値が活用できるのです。
- 仮説検定のプログラムをみて、理解することはできたが、いざ自分でゼロから作れと言われると作れないと思うので、Pythonをもっと勉強しなければならないなと思った。
- プログラムを作らなくてもよいように、js-Starを紹介しました。利用できるものがあるので、積極的に活用してください。
- プログラミングはコピペが重要と先生が仰ってたので自分も真似したい。
- プログラミングは命令を覚えることは重要ではなく、手順(アルゴリズム)を考えることが重要です。ここでこういう操作をするとできると分かれば、検索すれば該当する命令が出てきます。共通テストは擬似言語ですから、命令は日本語だし、見たことない命令には説明があるので、心配いりません。
- 数学の授業でやった時よりも、仮説検定と反復試行を理解できた。というより、やっと意味が分かったと言った方が正しいかもしれない。
- そんな相乗効果を期待していたので、このような感想はとてもうれしく思います。
- 統計処理には、数学で学習したデータの分析を用いた。ただ、本来なら膨大な計測を行わなくてはならない確率計算などをプログラミングによってコンピュータにさせるというのは情報分野に基づいている。振り返ると、統計処理は数学と情報が融合した面白い作業だと感じた。先生のデータの分析に関する説明が、正直なところ他の数学の教師よりも分かりやすいと感じた。本質をついた説明をしてくださっているので、とても理解しやすい。
- 数学で一度やっていて、用語も聞き覚えはあるし、コンピュータで計算しちゃうので計算も頑張らなくてよいわけで、どう「使ったらよいか」だけを説明しているので、そりゃぁ数学の先生よりわかりやすいはずです。おいしいところだけやっているんですから。
- いつもグループワークで使用しているword、PowerPointでの共同作業もデータ管理システムがないと成立しないものだということが分かった。ただ、どうしても共同作業にはラグが生じることがある。このラグを解消するためにはどの機能・性能を向上させたらよいのだろうか。数学の単元で1に苦手なのが確率、2に苦手なのがデータの分析な私は今までただその単元を嫌うだけだった。しかし、今日その有能性を知ってしまった…。これからはもう少し向き合おうと思う。
- 処理するデータベースサーバの性能を向上することが必要です。コストがものすごくかかるので、許容できるタイムラグによって使い分けていると思います。共同作業なら少々のタイムラグが許されますが、銀行の決済は許されませんよね。
- 数学でならったデータの活用の式の使い方を情報で習い、実際に探求で実践するという一連の流れが学校のなかで揃っているのがとてもいい学習環境だと思った。
- 情報と探究は親和性が高く、情報で学んだことを活かせるようになっています。問題解決ですからね。今回はそこに数学も絡んできているので、より濃密な繋がりが感じられると思います。積極的に活用することで、深く学んでください。
- データモデル、すなわちデータを扱う枠組みというのが重要であるというのが分かった。また、非構造化データにはどんなデータモデルがあるのか、そもそもデータモデルは非構造化データに存在するのか、気になった。
- chatGPTに聞いてみました。非構造化データベースとして有名なNoSQLのデータモデルには「ドキュメント型」「キー・バリュー型」「グラフ型」があるそうです。
- これまでプログラミングをやってきて、プログラミングはプロでも全て覚えている訳ではなく、どういう動作をさせたいか、明確にし、順序だててどんな関数や構文が必要なのか探し当てるとこが大切で、実際の関数などはインターネットや本から引っ張ってくれば良いのだと知れたので、授業で習ったものはしっかりと覚えて、それ以外のものは調べながら身につけていきたい。
- 階層データモデルの例を聞いてパソコン内のフォルダーのほとんどはこの枠組みで扱われていると気づいた。このようにデータを構造化することで現代のあふれる情報に対応しているので身近なところでも情報を整理したいときには構造化を意識するとよいのだろうと感じた。
- 数学は理論や道筋を学び、情報はそれを活用し効率的に日常に生かすことを考える強化だと思った。
- 数学の授業の時も思っていたが改めて計算ができることよりも式の意味が理解できることの大切さを再確認できた。
- 4つ以上のデータを円グラフで表すことはやめた方がよいということに関心を持った。地理の資料ページを開けば一度は目にするであろう円グラフ。大小関係が直感的につかみやすい反面、占める割合が小さなデータは、グラフ上の扇形の面積が小さくなり、表しにくくなってしまう。データを分かりやすく伝えるためにはどうすればよいか。具体的な分布においてはヒストグラム、変化を知るには折れ線グラフ、全体的な傾向をつかむには散布図あるいは箱ひげ図など使い分けが大切になってきそうだ。
- ツイッターやインスタで無意識に使っているハッシュタグは、データベースで扱いやすくするためのものであったと初めて知った。それと同じように、ネットで画像を調べるときも、画像に引っかかっているのではく、画像が載っているウェブの言葉に引っかかっているのだろうと思った。数1の内容が、情報の分野のプログラミングで簡単に表して結果まで出せたので、純粋にすごいと思った。しかも、難しいことはやっていなくて今まで習ったことで組み立てていた。書かれているプログラミングから理解した方が、文章で説明が書いてあるよりも、分かりやすいと感じた。
- 仮説検定で仮説が正しいといえるかどうかの判断が、数学はきっちりと数字のみの判断である一方、情報は状況に応じた緩やかな判断で、理論的な仕組みを理解する「数学」と実生活に応用していく「情報」の学習目的の差を感じられたような気がした。
- 仮説検定も基準を変えればいいように印象操作ができることが分かり、闇が深いなと思った。
- 期末考査で仮説検定の問題が出て、30回とあるサイコロ投げたら6の目が1回しか出なかったが、6の目が出にくいと判断できるかという問いと300回、サイコロを30回投げた実験で6の目が出た回数結果の表が与えられました。通常の問題なら、とあるサイコロで6の目が10回出て、普通のさいころで300回ぐらい実験した結果において6の目が30回中10回から最大値12回出た度数を使って0.01よりも小さな値が出て「6の目が出やすい」と書けばいいのですが、今回は「出にくい」と「30回中6の目が0回、1回の度数を使う」という点がいつもと反対で、正解はしたものの理解できないままでした。とくに30回中6の目が0回と1回を使い、1回から最大値12回までの度数を使わないのか分かりませんでした。しかし、今日の授業で、通常の問題で使っていたのは表の右側の、数が大きい方の片側検定で、テストの問題は表の左側の、数が小さい方の片側検定を使っていたのだとわかりました。
- 計算はいくらでもできることから、データを集める段階が1番大事だとわかった
- 情報の授業ではjs-STARやsAccessなど面白いツールを使って学習することができて楽しいと思った。数学は大事だと思った。
- 情報の論理と数学の論理は似ていることもあって仮説検定の考え方はすごくよく入ってきた。今回の内容は普段の生活に活用できるようなことが多かったので今からでも将来に活用できると思った。情報の便利な部分が多く見れてよかった。
- 数1で仮説検定を学んだ時は特に疑問に思わなかったけど、よく考えてみたらコイン投げを何千回も繰り返していたら、仮に正確に表と裏が記録できていたとしても、集中力が切れたり、手が疲れてきたりすることによって結果が変わるから、正確な確率を求める事が出来るわけがなかったことに気づいた。プログラミングができるようになると色々な事に使えて楽しい。
- 数1のデータの分析の授業で「情報の授業でコンピュータ使って同じようなことやるよ」と言われた日には、「じゃあ今頑張って計算する意味ないじゃん」と思ったが、実際に今日授業を受けて、計算の過程や理論をきちんと理解しているからこそ、ツールでの計算を使いこなせるのだとわかった。(そうじゃないと仮説検定や相関の判定を行っても数字しか見れなくなっちゃう)
- 数学でデータの分析を学んだが、計算はコンピューターの仕事なので、あくまで理屈を理解して適切に利用するためにある単元なのだろうと思った。統計について理解することで、それを自分で利用するだけでなく、企業などが都合よく見せているデータに騙されることもなくなるのかなと思った。
- 数学で数字を自分で使うことで考え方を身につけ、情報で生かすことが大切だと思った。仮説検定で、数学の問題では、「~かどうか」を問うので、片側しか聞いたことないのかもしれない。
- 数学で知り、情報で使い方を知り、探究で活用する
- 数学の確率やデータの分析の授業はとにかく計算量が膨大で敬遠していたが、その計算という過程が取り除かれたことでそれらの分野が今回の授業ではおもしろく感じられた。
- 数学の授業で計算式の立て方・理由を学び、情報でその使い方などを学び、探究活動で活用することができるのがいいと思いました。数学的、情報的それぞれの目線でみると違うもののような感じがしておもしろかったです。
- 数学は何か特別な職業につかない限りあまり生活に生かされないものだと考えていたが、今回の授業で仮説検定は将来も使う可能性があると感じた。数学と情報とのつながりも深いと思った。
- 非構造化データをコンピュータによって構造化できなくないが時間も含めたコスト面でそれ相応の利益がでないからタグ付けによって構造化していることに驚いた。
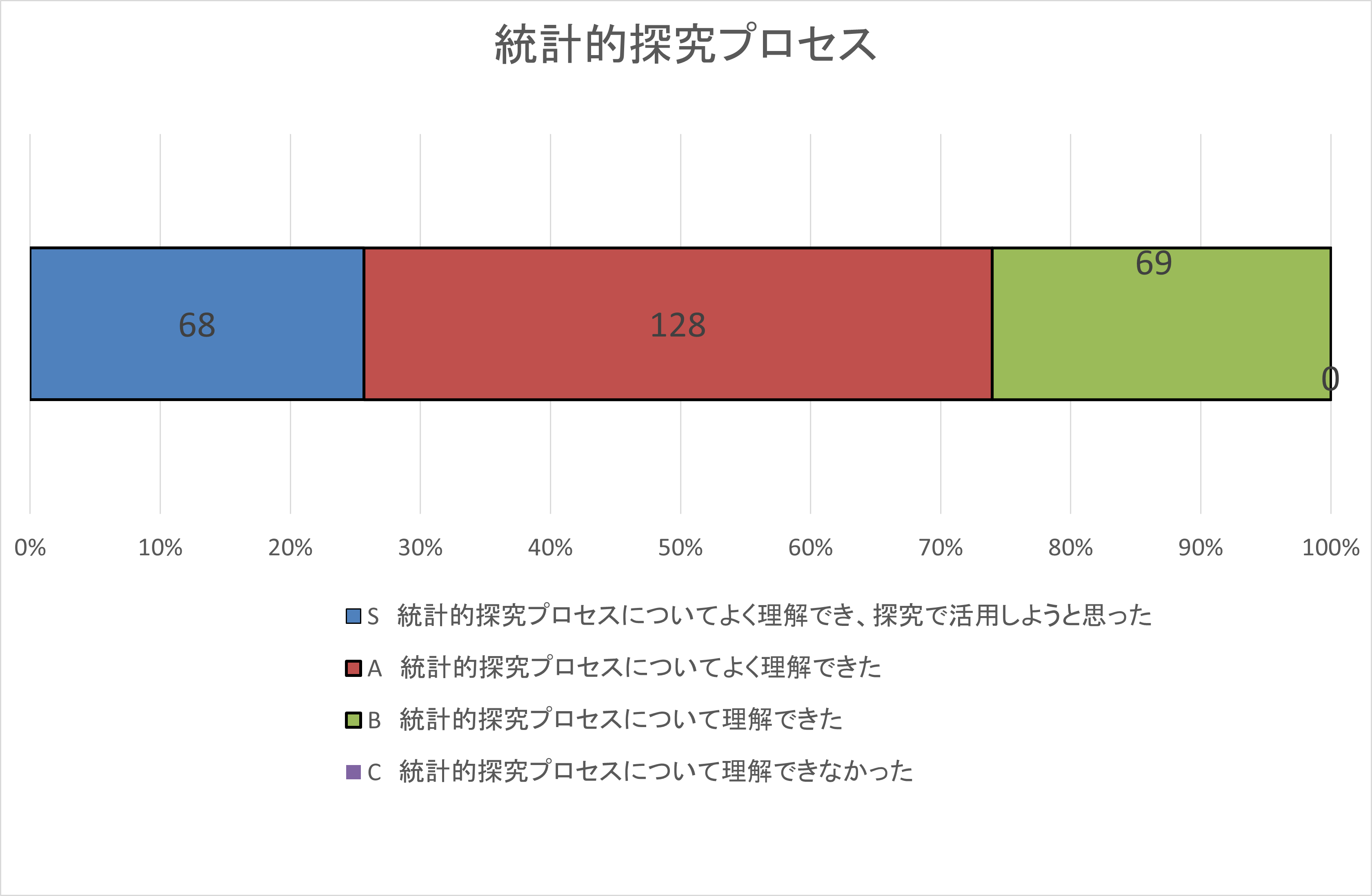
自己評価集計
ワードクラウド
- 3つのキーワード

- 感想や気づき

テキストマイニング 無料ツール by ユーザーローカル
前のページに戻る