2022情報I 3学期
第5回 授業の振り返りより
質問より
無印は皆さんの回答、☆は先生の回答です
- AIとデータベースの違いや、関係はどんなものか。
- ☆AIはコンピュータで動作するソフトウェアで、データベースはデータを管理操作するためのソフトウェアとデータのことを指します。まったく別のものですが、同じコンピュータで動かすことができます。データベースのデータをAIで分析することはできると思います。
- index.phpとは何かhtmlとは違うのか
- index.phpはPHPという言語で書かれた動的なWebページです。内容はHTMLで書かれていますが、静的なページと見分けが付くようにPHPという拡張子が付いています。
- RFIDなどもデータとしてサーバに送られるのですか?また、そのデータは店舗内に送られるのか、本社に送られるのかどちらでしょうか
- RFIDタグは色々な所で使われていますが、”店舗内”という言葉が質問に含まれていたので、ファーストリテイリング(ユニクロ,GUなどを経営している企業)について調べてみました。 とりあえず公式ページでRFIDタグについて検索をかけてみたところ、生産した時点で、すべての商品に固有の(同じ商品でも異なる)RFIDタグを取り付け、検品、輸送、棚卸、納品、販売までの商品の流れを全て管理できるようにしているとのことです。在庫管理に使われているということですね。また、サプライチェーン全域(つまり世界レベル)の在庫情報を確認できるとのことなので、少なくとも在庫管理を行うサーバーがあるようです。 (参考画像-9ページ: https://www.fastretailing.com/jp/ir/library/pdf/20181011_jimbo.pdf ) さて次に、ファーストリテイリングが持っている特許情報を調べてみましょう。 特開2020-175970 特開2017-228137 RFIDタグを利用した在庫管理に関する特許は主にこの二つですね。 特許の要約を見てみると、 RFIDのデータを読み取った後、ホストコンピューターに保存し、POS装置や防犯装置で利用していること、 店舗ごとに集約されたデータはネットワークを介してサーバーへ保存されることが分かります。 長くなりましたが、ファーストリテイリングの場合、RFIDは本社レベルの(国内にあるとは限らないが)サーバーへ保存される、というのを回答としたいと思います。Google検索をしたときに上の方に出てくるニュース記事や個人ブログは読みやすいですが、公式サイトに掲載されているニュースリリースや、特許情報などを見てみるのも面白いですよ。
☆会社のデータ戦略によって違います。
- sAccessで、「カウント」の前に「選択」を設定する必要があるのはなぜですか。
- 「選択」をしなくてもどのフィールドに関して「カウント」をするのかを入力すれば「カウント」は使えます。
- sAccessで操作コマンドを入力する際に、なぜ正しいコマンドの順序性に並び替えないといけないのですか。
- [A,B,C]というリストがあったとしましょう。[A,B,C]から[C]を取り出す操作をした後に、[C]から[A,C]を取り出すことはできるでしょうか?もちろんできませんよね?しかし、[A,B,C]から[A,C]を取り出す操作をした後に[A,C]から[C]を取り出すことはできるでしょう。 sAccessの場合も、元のデータに「絞り込み」や「並べ替え」などの操作を順々に加えているので、存在しないデータを扱おうとするとエラーが出るのです。
- sAccessとExcelの違いは命令を記号でやるか文字でやるかということだけですか。
- Excelも厳密にいうと文字も使うと思いますが、 イメージとしてはあっていると思います。
☆まったく違うもので、sAccessはデータベース、Excelは表計算ソフトです。どちらもデータを表で表示していますが、sAccessはデータを直接いじらず、命令によって見え方を変え分析するものです。
- sAccessにおいて、コマンドの順を変えてもエラーが出ずに成り立つことはあるのか。
- あります。例えば、「表示 売上データ」「結合 商品データ」「選択 時間帯 朝」「カウント 商品名」の順にコマンドが並んでいる場合、「結合 商品データ」「選択 時間帯 朝」の二つのコマンドの順を変えてもエラーは出ません。
- sAccessの表示、選択、結合が何を意味して何が違うのですか?
- ☆表示はテーブルの表示、選択はフィールドの選択、結合はテーブルの結合を意味しています。実行結果は見たとおりで、表示されたり、選択されたり、結合されたりします。画面を最大化して、テーブルの様子がどう変わるかを見るようにすれば、それぞれの操作の意味も分かるはずなんですけど。
- データが数千件程度なら手動でクリーニングできなくもなさそうですが、数万件、数十万件となった場合はどうするのでしょうか?
- ☆ある程度ルールベースでクリーニングします。それでクリーニングできるようなデータを集めることが大切なんでしょうね。皆さんの入力、結構ひどかったぁ~。
- データの分析の授業に向けて数学Iの復習は必要ですか。
- 仕組み(公式)がわかればいいのではないでしょうか。計算はきっとコンピュータにさせるはずです…
☆公式は必要ありません。どういった処理ができて、どういった値が得られ、それがどのような意味を持つのか、仕組みを復習しておいて下さい。
- データベースとサーバは何が違うのですか。
- サーバの中にデータベースの機能があるのだと思ってます。
☆データベースはソフトウェアです。あなたのパソコンだけでデータベースを利用するなら、あなたのパソコンにデータベースソフトをインストールします。電話帳アプリもデータベースソフトの一種ですね。複数の人で使う場合は、同時に利用できるサービスとして使えるように、サーバと呼ばれるパソコンにインストールして使います。データベースはデータを整理して管理するためのソフトウェアです。○○サーバといわれるソフトウェアはデータに基づきサービスを提供しているので、データベース的な機能も含まれていますが、必要な機能だけに限定されたものです。さまざまなデータを安全に大量に蓄積するためには、データベースというデータベース専用のソフトウェアが必要です。
- データベースの分散のさせ方に法則はありますか。
- ☆法則とはどういうことかちょっと理解できないのですが、分散データベースは分散データベースを構成するハードウェアとソフトウェアによる高度なシステムで、「データベーススペシャリスト試験」に合格できるぐらい学習するとわかるようになると思います。
- データベースの分散管理のところで、グーグルに反応が速いものと遅いものがあるというのは性能の問題ですか。それともサーバの権限のように何か設定するのですか。
- ☆「Google検索のサイトはいつも同じようで実は複数あり、それぞれのデータベースが順に更新されタイムラグがあるので、最初に更新され新しいページがすぐに検索できる反応の速いものと、更新順が遅く反応が遅いものがある。」という話をしました。性能の問題でも権限に関係するものでもありません。設定で変化するものでもありません。どのサイトに当たるかは単純に運です。
- データベースは地域単位で分載されていると習いました。では、さまざまなデータベースをまとめたものというものは存在するのでしょうか?
- ☆データベースはインターネット上のサービスではないので、共有のものではなく、企業などが自社で使うために構築するものです。大規模になると負荷分散のために分散させますが、分散方法はさまざまです。一つの考え方として地域ごとに分散すると都合がよい例を紹介しました。分散したままで処理できるのであれば分散したまま運用するでしょうし、まとめたものが必要ならまとめたものを構築して運用するでしょう。データベースを利用する会社やデータベースを構築する会社の考え方で決まります。
- データベースを分散させることができると授業で触れていたが、その場合は欲しい情報を抜き取るのに困ったりしないのだろうか。その欲しい情報が分散されたデータベースのどれにあるのかが分からないのではないのだろうか。
- 第六回で習ったデータベース管理システムが登録されているデータを管理するため、基本的にそういう事態にはならない。(今アクセスしているデータベースに欲しい情報がなくても、ほかのデータベースからそれを探して持ってきてくれる。)
- なぜデータのクリーニングをコンピュータでできないのですか。
- コンピュータだと間違いの定義ができないからではないでしょうか。もちろん値段が国家予算を超えるものなどを除くことはできるのでしょうが消しゴム1万円などを除くことが難しかったり同じものでも違う名前(例えば「三菱鉛筆」と「書き方鉛筆」など)で書かれているのもや似てる名前だけど違うもの(「ペプシコーラ」と「コカ・コーラ」)の区別を定義することができないからなのではないでしょうか?
☆人間の間違いってコンピュータでは予測不能な自由度があるのです。一度データクリーニングをやってみると、わかります。こんなの自動化できないって。いずれできるようになるとは思いますが。
- ネット銀行のメリットはさまざまあると思いますが、デメリットはありますか。
- ☆特にないです。営業の電話もかかってこないのでとてもよいです。
- バーコードのテーブルでは、同じ商品でも人によって商品名の書き方が違うので分析が上手くできませんでした。キーワード検索のようなことができればいいと思ったのですが、何か解決策があれば教えてください。
- ☆第5回の時点で配布したバードードデータのデータベースは、(1)データクリーニングができていない(2)バーコードのフィールドがおかしい(3)正規化されていない、といった理由で上手く分析できません。データベースとして機能しない例として見てください。
- バーコード番号が国ごとに違うのはどのような理由があるのかなと思った。
- ☆国ごとに違う番号を使う取り決めがあるのです。国際的にはEANコード(European Article Number)として番号の付け方、バーコードの作り方が定められていて、日本のJANコードはEANコードに準拠しています。
- 銀行でタイムラグが出ないようにするにはどうするんですか。
- ☆データベースシステムにそのような機能が備わっています。ここには説明を書き切れないので、詳しくはこちらを見てください。
- 銀行のデータベースで、リアルタイムでデータを操作して且つその順番も正確に管理するシステムには、ブロックチェーンも使われていますか。また、ほかにどんな技術が使われていますか。
- スイスのUBSという銀行などでは、ブロックチェーンが活用されているようです。他の銀行などでも、この技術は注目をあびていますが、実証実験中です。
- 屑データを取り除いてくれるAIを作ることは今後も絶対にできないのか、それはなぜなのか
- ☆「絶対できない」という説明はしていないはずです。データクリーニングを一度やってみると、コンピュータに指示することが難しいことがわかります。屑みたいな使えるデータと、まともそうな屑データと、臨機応変に判断しなければならない場面が多数出てきます。
- 授業で扱ったsAccessのように、データベースのデータは基本的に並べて表のようにして閲覧者に表示できるのか疑問に思った。
- ☆閲覧者って誰のことでしょう。データベースを利用する人は、データベースに問い合わせ言語を使って問い合わせます。「表示 商品データ」のように問い合わせると、表形式のデータが取り出せるという仕組みです。
- 書籍のバーコードは何故二つあるのか、また、一般のバーコードを使用することは何故ないのか
- 本は流通している数が多いので、より詳細な管理が必要だからです。上段は国際標準図書番号という世界共通の番号で、下段は分類コードと価格コードをまとめた、日本図書コードです。 ちなみに、本に二つのバーコードを記載するのは、日本独自です。
- 分析することはなぜAIではなく人間にしかできないのですか?
- AIは、基準が与えられてそれに〇か×かしか判断することができないからだと思います。(所詮プログラミングに従っているだけ) だから、解決策や、問題の原因を探る思考の部分は、人間の方がまだ賢いんだと思います。
- 曜日や年齢層などの情報以外にも、その商品のジャンルなど他にもどんなのがあるのか気になりました。
- ☆sAccessのプリセットDB[コンビニ]にはありません。実際に使われているコンビニのデータベースには必要に応じて結合できるよう、ジャンルなどの項目のテーブルが用意されていると思います。どんなのがあるのかは、コンビニの本社に務めない限りわからないと思います。
- 論文のデータベースで最も信頼度の高いものはあるんでしょうか
- 査読付きジャーナルに掲載されている論文は、分野にかかわらず、最も信頼できる情報源だそう。
☆chatGPTに聞いてみました。 PubMed Central (PMC)/Scopus/Web of Science (WoS)/Google Scholarだそうです。英語の読み書き、必須ですね。
感想より
- データベースの仕組みは、それ単体で覚えるのも大切だと感じたが、データベースに人がどのように関わっているのかや、データベースに人がどのように組み込まれているのかを考えてみるのもまた大切だなと感じた。受験期毎日のように使っていた塾の近くのコンビニで一度に5から10本ほど羊羹を買っていたら、最初レジの横に10本入りの箱が一つしか置かれていなかったのが、場所がカロリーメイトやチョコレートバーの置かれた場所に2、3箱置かれるようになったのはコンビニを育てていたんだなと感じた。
- 育ててますね。消費動向を逃さないように商品を置いておくことが、店側の収益確保に必要なことですからね。データを介してWin-Winの関係になりますね。
- 数学に外れ値をはじく決まりがあるように、バーコード番号における「外れ値」を自動化する仕組みができないかなと思った。
- バーコード番号の入力誤りはチェックデジットを計算するとわかります。計算方法はこちらを読んでみてください。
- データベースは入力する際のミスを改善できれば非常に有用なものだと思った。
- 入力時に入力内容の確認画面に推移して、[これでよろしいですか]と確認させる方法もありますが、面倒だと思う人も多く、確認せずに[OK]を押す人も多いようです。結果、確認できていないデータが入力されちゃうんです。
- コンビニの例は面白いと思った。どの商品がどの年齢層に売れているかという情報から売上向上のためどんな対策をしていくかというプロセスは、ある種普段の勉強につながる部分があると思ったからだ。例えば、どの教科のどの分野が入試で問われているかという情報から合格点をとるためにどんな対策をしていくかという行動はそれに当たると思う。
- 知識を問う問題については、AIを利用して苦手をあぶり出し強化するようなものや、忘れた頃にひょっこり尋ねて定着を図るようなものが実用化されています。ただ、知識だけでは解けないのが最近の大学入試問題ですよね。共通テストであっても、思考力が問われるようになっています。
- society5.0ではビックデータを管理して超効率化社会が実現する、という話を思い出した。ビックデータの管理もデータベースなのか、だとしたら相当な数のデータベースが無いととてもデータが収まりきらなそうだと思った。そんなに沢山のデータベースの入っていて、サーバは耐えられるものなのか疑問に思った。
- たくさんのサーバを使って分散データベースを作ったり、昨日やデータによってサーバやデータベースを使い分けるなど、負荷分散の方法は多数あります。データ自体はいろいろな場所においたまま、データがどこにあるかだけを示すデータベースもあります。
- データベースに上限はあるんですか。あるなら上限を教えてください。
- ソフトウェアの性能、インストールしたコンピュータの性能によって決まるので、上限はあるということしか言えません。
- データクレンジングなど、コンピュータがやったほうが早く終わるようなことを人間がやらなくてはいけないのは、研究の目的や本当に必要なデータを知っているのは、コンピュータではなくデータを分析する人自身だからなのだと思った。
- そういうことなんです。ルールベースのコンピュータ的杓子定規ではダメで、何が必要かを加味した臨機応変な人間の判断が必要になることが多いのです。
- 自販機にもPOSシステムが使われているのか気になった。
- 最近の自販機は電子マネーで決済できますよね。そこから、通信機能を持っているということが分かると思います。このような自販機の販売状況、内部の在庫状況は集中管理されているはずです。自販機の会社の人、トラックを降りたらすぐに補充する商品を荷台から取りだしてますよね。何が不足しているか、あらかじめ知っているからなんです。
- 自分のやっているゲームでコースごとの勝率やゲームの大事なアイテムが出るタイミングを記録していたが、これもデータベースなのかと思った。
- 関連するデータを同じ形式で蓄積したものがデータベースですから、まさにデータベースですよね。皆さんの身近なところでは、スマホの電話帳なんていうのも立派なデータベースなんですよ。複数の人で使うデータベースはサーバにインストールしますが、端末にインストールされた個人で使うデータベースも身近なところで活躍しているのです。
- webapi を叩いた時、sqlサーバからデータを抽出するコードを書いた時、sqlの書き方は大体学んだのでデータベースやテーブルの理解は深かったと感じる。その為sAccessよりもコマンドラインでの作業の方がわかりやすく感じた。
- SQL(Structured Query Language)はデータベースを操作する言語です。SQLを理解した人から見ると、sAccessはちょっと歯がゆいですよね。
- 店内でしか使えないバーコードを使用する利点は何なのか気になった。
- スーパーのお弁当、コンビニのサンドイッチ、別のお店で売ってないですよね。でもバーコードで処理したいですよね。コンビニによっては消費期限のデータを持たせ、期限切れの商品を売らないようにしているところもあります。
- 店の売り上げはデータベースの分析ができているかどうかが決め手といっても言ではないと思った。
- POSが最初に導入されたアメリカでは、導入しないと潰れるぐらいのインパクトがあったようです。
- インターネットでショッピングをする際、あなたへのおすすめ商品が出る理由が分かり、データベースのメリットを改めて感じた。
- 今回の授業で、簡易的なデータベースをはじめて使ってみてデータベースにすごく興味を持った。これから探求とかで、webAPIだのクラウドソースだの用いて、AI開発に使えそうだなと思った。
- POSシステムはデータベースをうまく利用して経済をよりよくする(=客によりお金を使ってもらう)すごく現代の技術を活用していると思った。データベースは情報が一つでも違ってしまうと多大な影響をもたらしてしまうことが分かった。やはり間違えを起こすのは人間だと思った。
- sAccessで子どもに売れている商品を調べる時に、その前に使ったコマンドをそのままにした状態で子どものコマンドを追加したためエラーになったが、そこからコマンドを入れ換えることで求めたいデータを得る仕組みを理解できた。エラーから仕組みを理解して改善できたことが楽しかった。
<
- データベースを作るにあたって、データモデルにあったデータを正確に集めることが大切だと実感した。データ自体には手を加えずにデータを用いてその特徴などを調べることができるというのはデータベースの利点となるが、それはデータが正確に集められていることが前提だと思った。なぜなら、データクレンジングの際に正しくないデータを除去しきれなかったり正しいデータを変えたりしてしまったら、データに手を加えなくても良いという利点をつぶしてしまうことになってしまうから。
- ペアワークでいつもと違う人と組むのはとてもいいなと思った。自分にはなかった視点から物事を捉えられるので、視野が広がった気がした。ただ、ペアワークをやるにしては話し合う時間が短かったように感じた。私は普段コンビニを使わないが、今日の話を聞いて育ててみたくなった。
- 今までの認識は、「データを集めるまでが大変で、集め終えたらコンピュータが頑張ってくれる」というものだった。しかし、実際には適切なデータの選択、不要なデータの削除、適切な分析項目の設定、思考とプロセスの簡略化など、多くの操作・技能が必要なことがよくわかった。情報を適切に処理する能力は今後探求で必須になってくると思う。次回からの数学的アプローチも踏まえつつ、実践で使えるレベルまで能力を向上させたい。
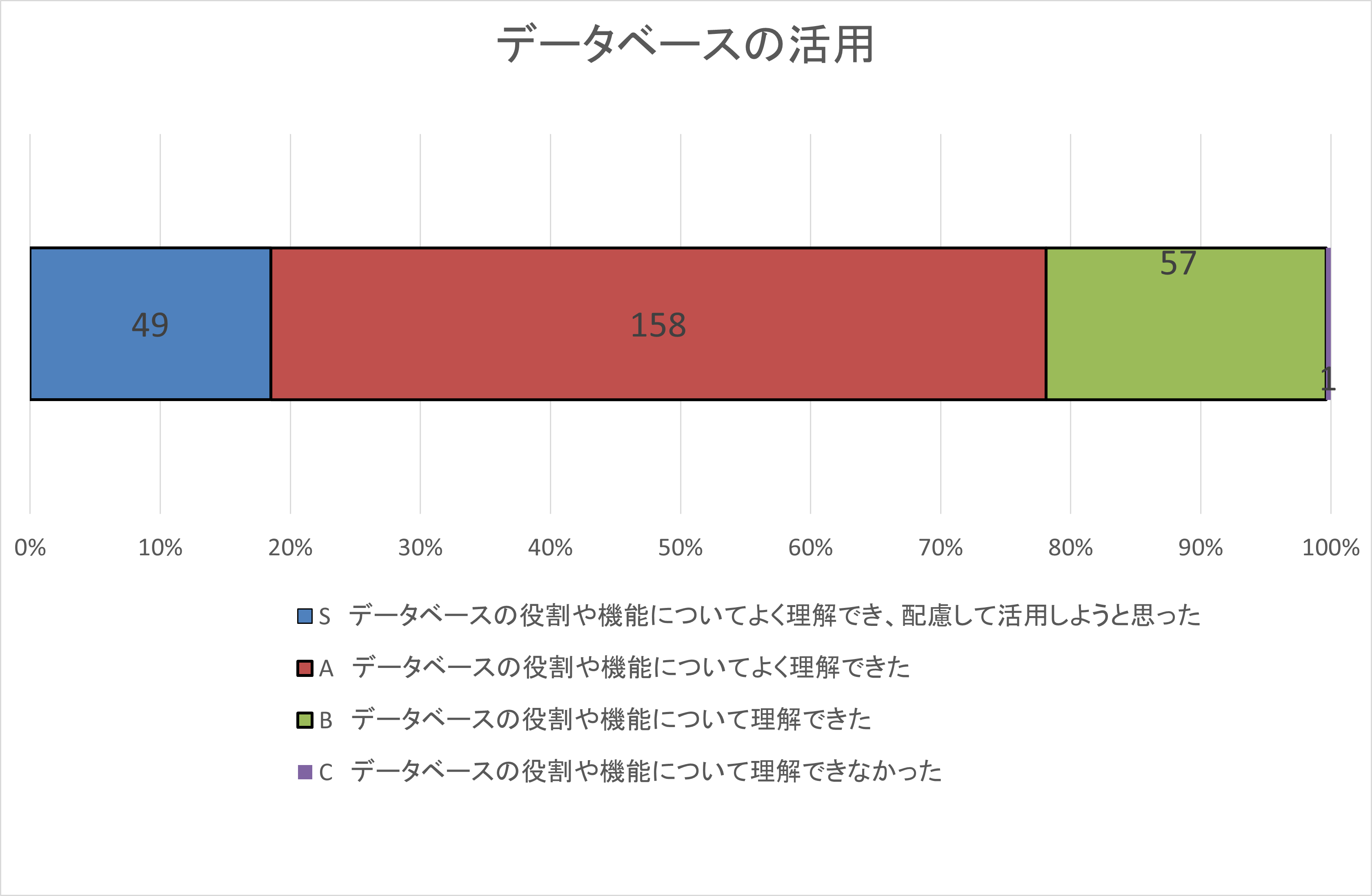
自己評価集計
ワードクラウド
- 3つのキーワード

- 感想や気づき

テキストマイニング 無料ツール by ユーザーローカル
前のページに戻る